딥러닝을 이해하기 위해서는 인공 신경망을 알아야함
초기 인공 신경망인 퍼셉트론에 대한 설명 정리해보겠음
퍼셉트론(Perceptron)
다수의 입력으로부터 하나의 결과를 내보내는 알고리즘

퍼셉트론은 인간의 뉴런 동작 원리와 유사함
뉴런은 가지돌기에서 신호를 전달받고, 축삭돌기를 통해서 신호를 전달함
x는 입력값, W는 가중치(Weight), y는 출력값임
파란색 원은 인공 뉴런임
각각의 입력값에는 각각의 가중치가 존재하는데 가중치의 값이 크면 클수록 해당 입력 값이 중요함
(실제 인간 뉴런 동작에서 신호를 전달하는 축삭돌기 역할을 퍼셉트론에서는 가중치 W가 대신함)
각 입력값과 그에 해당되는 가중치의 곱의 전체 합이 임계치(threshold)를 넘으면 인공 뉴런에서 1 출력
그렇지 않을 경우에는 0 출력
다층 퍼셉트론(MultiLayer Perceptron, MLP)
앞의 설명은 단층 퍼셉트론이었음
다층 퍼셉트론은 단층과 달리 입력층과 출력층 사이에 은닉층이 존재함
은닉층이 2개 이상인 신경망을 심층 신경망(Deep Neural Network, DNN)이라고 함
심층 신경망을 기계가 학습시켜 정답을 출력할 때까지 가중치를 찾는데
이 과정을 딥 러닝(Deep Learning)이라고 함
model = nn.Sequential( nn.Linear(2, 10, bias=True)
nn.Sigmoid(), nn.Linear(10, 10, bias=True),
nn.Sigmoid(), nn.Linear(10, 10, bias=True),
nn.Sigmoid(), nn.Linear(10, 1, bias=True),
nn.Sigmoid() ).to(device)
모델 구현의 한 코드를 가져왔는데 입력층은 2개의 특성을 가졌고 그 다음층(a)은 10개의 특성 가짐
10개의 특성을 가진 은닉층(a)의 다음층(b)도 10개의 특성을 가짐
10개의 특성을 가진 은닉층(b)의 다음층(c)도 10개의 특성을 가짐
10개의 특성을 가진 은닉층 (c)의 다음층인 출력층은 1개의 특성을 가짐
이렇게 코드를 연속적으로 작성해야 하나봄
기울기 소실이나 기울기 증폭을 방지하는 법
앞의 글에서 시그모이드 함수를 쓰면 기울기가 0에 수렴해지면서
역전파 과정에서 입력층 방향으로 갈수록 기울기 소실이 발생할 수 있다함
1. 리키 렐루 사용해라
(은닉층에서 시그모이드 함수는 지양하고
그냥 렐루 쓰면 죽은 렐루 문제가 발생할 수 있으니 리키 렐루 써라)
2. 가중치 초기화해라
같은 모델을 훈련시키더라도 가중치가 초기에 어떤 값을 가졌냐에 따라 훈련 결과가 달라짐
1) 세어비어 초기화(Xabier Intialization)
각 층의 입력과 출력 뉴런 수를 고려하여
균등 분포나 정규 분포로 초기화하는 것
nin: 이전 층의 뉴런의 개수 nout: 다음 층의 뉴런의 개수
but 세어비어 초기화는 시그모이드 함수나 하이퍼볼릭 탄젠트 함수와 같은 S자 형태인 활성화 함수와 함께 사용해야함
렐루랑 쓰면 성능 안 좋음
그럼 렐루는 뭐랑 써요???
2) He 초기화(He initialization)
He도 정규 분포나 균등 분포로 초기화하는데
세이비어 초기화와 다르게 다음 층의 뉴런 수를 반영하지 않음
즉 nin만 이용함
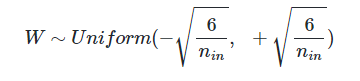
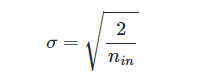
3. 배치 정규화(Batch Normalization)
배치 정규화는 내부 공변량 변화 문제를 줄이기 위해 설게된 방법
입력 데이터의 분포를 정규화하여 안정된 학습 환경을 제공함
(내부 공변량 변화란 학습 과정에서 층 별로 입력 데이터 분포가 달라지는 현상)
배치 정규화는 각 층에서 활성화 함수를 통과하기 전에 수행됨
입력에 대해 평균을 0으로 만들고 정규화 진행(평균 0 분산 1)
정규화된 데이터에 스케일(크기)과 시프트(위치) 수행
gamma와 beta 이용(각각을 g랑 b라 하겠음)
-> g>1이면 데이터의 분포를 더 크게 g<1이면 더 작게 만듦
b는 위치를 조정하는 것이니까
데이터를 평균 0에서 다른 값으로 이동시킴
-> b>0이면 데이터를 오른쪽으로 b<0이면 왼쪽으로 이동

시그모이드 함수의 분포만 생각해도 값이 매우 크거나 매우 작으면
기울기가 완만해지면서 0에 가까워짐
배치 정규화를 하면 평균 0 분산 1에 가까워지면서 입력값이 안정적으로 유지됨
배치 정규화의 한계는
너무 작은 배치 크기(가중치 업데이트 수행하기 위한 데이터 샘플 수)에서는 잘 동작하지 않음
RNN에 적용하기 어려움
(RNN 나도 아직 안 배워서 먼지 모름 ㅜㅜ)
지금까지 우리가 배운 신경망들은 다 출력층 방향으로 진행됨
근데 출력층 방향으로도 가고 은닉층의 값이 다시 입력으로 돌아갈 수 있음
뭔 소리냐고???
은닉층의 시간(t)에 따라 다시 이전 시간(t-1)으로 돌아가며 그 다음 시간(t+1)의 입력으로 사용된다는데
이전 시점에서 계산된 은닉층의 출력값이 현재 시점에서의 입력값과 함께 사용된대요
순환 신경망(Recurrent Neural Network, RNN)
은닉 상태: 은닉층의 출력값으로 다음 시점 t+1에게 보내는 값
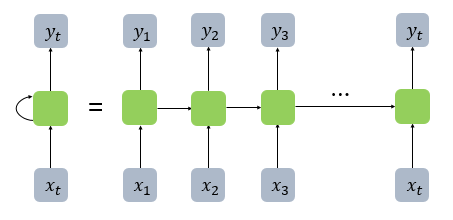
→ h 계산 → y 계산
x2 + h1 → h2 계산 → y 계산
x3 + h2 → h 계산 → y 계산



은닉층 수식은 이해가 되는데 출력층 수식은 생각지도 못했다
xt와 wy의 곱인 줄 알았는데 은닉층 ht와 wy의 곱이라니...

예시로는 하이퍼볼릭탄젠트 함수(tanh)를 이용했지만 렐루도 가능
양방향 순환 신경망(Bidirectional Recurrent Neural Network)
시점 t에서의 출력값을 예측 할 때 이전 시점의 데이터뿐만 아니라
이후 데이터로도 예측할 수 있음

주황색은 Forward States로 앞 시점의 은닉 상태를 전달받아 현재의 은닉 상태를 계산함
연두색은 Backward States로 뒤 시점의 은닉상태를 전달받아 현재의 은닉 상태를 계산함
두 개의 값 모두가 출력층에서 출력값을 예측하기 위해 사용
양방향에선 hidden_size가 2배가 됨
하나의 입력값에 주황색, 연두색 각각 두 개씩 생기니까 x2를 해야하나봄
출력 텐서는 순방향과 역방향의 은닉 상태를 결합해서 크기가 두 배되는데
마지막 은닉 상태는 순방향과 역방향의 은닉 상태를 개별적으로 저장해서
16/ 8, 8 이런 식인가봄
뭐라는거냐
'공부공부' 카테고리의 다른 글
| Langchain Langraph 멀티에이전트 공부 (11) | 2025.08.13 |
|---|---|
| [딥러닝] LSTM 모델과 CNN 합성곱 신경망 (3) | 2024.12.02 |
| [딥러닝] 혼동 행렬, 시그모이드 함수, 렐루 함수 등 (0) | 2024.11.26 |
| 2024 노벨 생리의학상 miRNA 유전자 조절 (4) | 2024.11.02 |
| 신호 처리를 위한 HPF 필터 (1) | 2024.10.10 |