구조방정식: 여러 변수들 간의 관계를 동시에 분석하는 고급 통계 기법
잠재변수(latent variable)와 관찰변수(observed variable)를 함께 다룰 수 있음
-> 보이지 않는 심리적·개념적 구조(잠재변수)를 실제 문항(관찰변수)로부터 추정하고, 그 구조들이 서로 어떻게 영향을 주는지 모델링하는 방법
왜 회귀분석을 안하고?
관찰변수만 가지고 분석할 때의 문제점
잠재변수를 사용하지 않으면 보통 다음과 같은 방식으로 처리함
- 여러 문항을 평균 또는 합산해 하나의 점수로 합침
- 이 점수를 변수로 사용하여 회귀분석 등에 투입
그러나 이 방식은 중요한 가정을 깔고 있음 -> 각 문항 점수에 measurement error(측정오차)가 존재하지 않음
하지만 실제 심리·사회과학 데이터를 포함한 거의 모든 설문 문항에는 반드시 측정오차가 존재함
SEM은 어떻게 해결하는가?
SEM은 각 문항을 잠재변수가 만들어낸 '신호(signal, 잠재변수가 진짜로 반영된 부분)' + '오차(error)'로 분리
- 잠재변수 = 우리가 진짜로 알고 싶은 개념
- 오차항 = 측정 과정에서 생기는 불완전성
SEM은 오차를 명시적으로 모델링하여 오차가 제거된 순수한 잠재구조를 분석하게 해줌
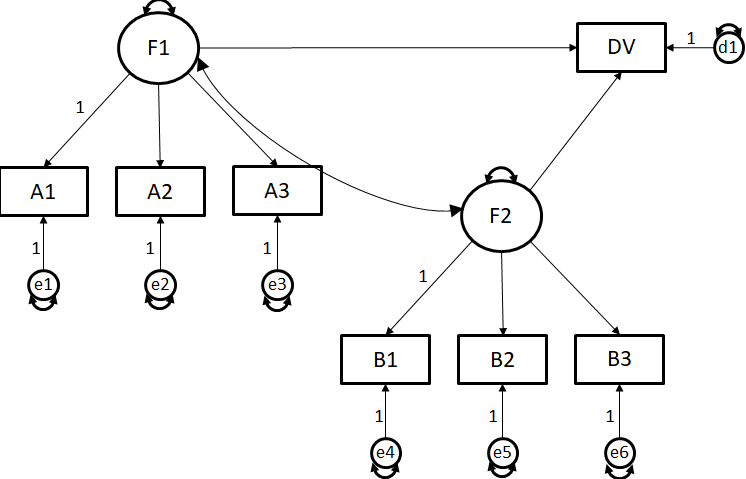
A1, A2, A3와 B1, B2, B3 그리고 DV 등은 직접 측정한 설문 문항임
F1, F2는 잠재변수임
E1~E6는 measurement error(측정오차)
논문들 읽어보면서 모르는 내용은 더 추가할게요 안녕
'공부공부' 카테고리의 다른 글
| [LLM] Talk Structurally, Act Hierarchically 코드 공부 (6) | 2025.08.17 |
|---|---|
| Langchain Langraph 멀티에이전트 공부 (11) | 2025.08.13 |
| [딥러닝] LSTM 모델과 CNN 합성곱 신경망 (3) | 2024.12.02 |
| [딥러닝] 퍼셉트론, 기울기 소실 방지, 순환신경망 RNN모델 (0) | 2024.11.28 |
| [딥러닝] 혼동 행렬, 시그모이드 함수, 렐루 함수 등 (0) | 2024.11.26 |